
Arquitectura y conceptos básicos
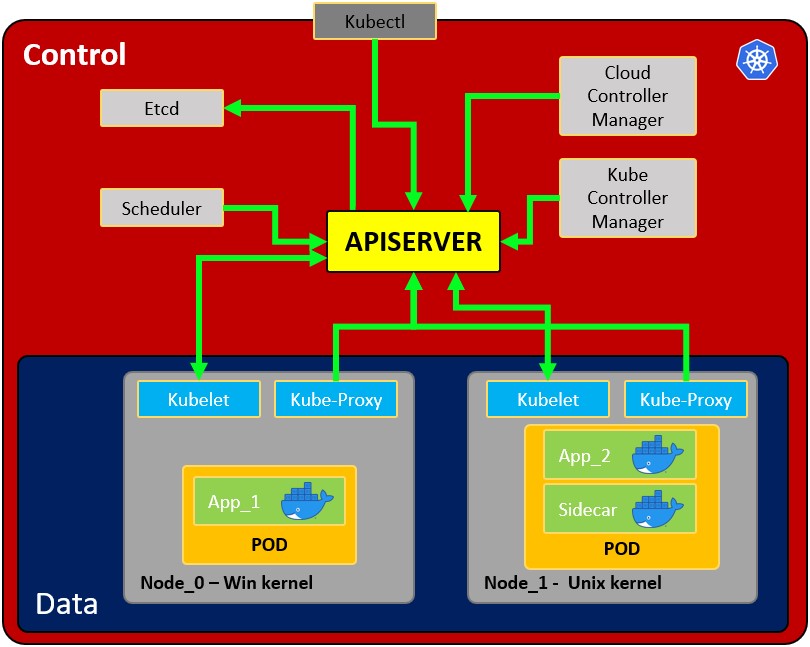
- Nodo : sistema operativo con pod o pods.
- Vaina : Envuelva alrededor de un recipiente o varios recipientes con. Un pod solo debe contener una aplicación (por lo general, un pod ejecuta solo 1 contenedor). El pod es la forma en que Kubernetes abstrae la ejecución de la tecnología de contenedores.
- Servicio : cada pod tiene 1 dirección IP interna del rango interno del nodo. Sin embargo, también se puede exponer a través de un servicio. El servicio también tiene una dirección IP y su objetivo es mantener la comunicación entre pods para que si uno muere el nuevo reemplazo (con una IP interna diferente) estará accesible expuesto en la misma IP del servicio . Puede configurarse como interno o externo. El servicio también actúa como un equilibrador de carga cuando 2 pods están conectados al mismo servicio. Cuando se crea un servicio , puede encontrar los puntos finales de cada servicio en ejecución
kubectl get endpoints
- Servicio : cada pod tiene 1 dirección IP interna del rango interno del nodo. Sin embargo, también se puede exponer a través de un servicio. El servicio también tiene una dirección IP y su objetivo es mantener la comunicación entre pods para que si uno muere el nuevo reemplazo (con una IP interna diferente) estará accesible expuesto en la misma IP del servicio . Puede configurarse como interno o externo. El servicio también actúa como un equilibrador de carga cuando 2 pods están conectados al mismo servicio. Cuando se crea un servicio , puede encontrar los puntos finales de cada servicio en ejecución
- Vaina : Envuelva alrededor de un recipiente o varios recipientes con. Un pod solo debe contener una aplicación (por lo general, un pod ejecuta solo 1 contenedor). El pod es la forma en que Kubernetes abstrae la ejecución de la tecnología de contenedores.

- Kubelet : Agente de nodo primario. El componente que establece la comunicación entre el nodo y kubectl, y solo puede ejecutar pods (a través del servidor API). El kubelet no administra contenedores que no fueron creados por Kubernetes.
- Kube-proxy : es el servicio encargado de las comunicaciones (servicios) entre el apiserver y el nodo. La base es una IPtables para nodos. Los usuarios más experimentados pueden instalar otros proxies kube de otros proveedores.
- Contenedor Sidecar : Los contenedores Sidecar son los contenedores que deben correr junto con el contenedor principal en la vaina. Este patrón de sidecar amplía y mejora la funcionalidad de los contenedores actuales sin cambiarlos. Hoy en día, sabemos que usamos tecnología de contenedores para envolver todas las dependencias para que la aplicación se ejecute en cualquier lugar. Un contenedor hace solo una cosa y lo hace muy bien.
- Proceso maestro:
- Api Server: es la forma en que los usuarios y los pods se comunican con el proceso maestro. Solo se deben permitir solicitudes autenticadas.
- Programador : la programación se refiere a asegurarse de que los pods coincidan con los nodos para que Kubelet pueda ejecutarlos. Tiene suficiente inteligencia para decidir qué nodo tiene más recursos disponibles para asignarle el nuevo pod. Tenga en cuenta que el programador no inicia nuevos pods, solo se comunica con el proceso de Kubelet que se ejecuta dentro del nodo, que iniciará el nuevo pod.
- Administrador del controlador de Kube : verifica recursos como conjuntos de réplicas o implementaciones para verificar si, por ejemplo, se está ejecutando la cantidad correcta de pods o nodos. En caso de que falte un pod, se comunicará con el programador para iniciar uno nuevo. Controla la replicación, los tokens y los servicios de cuentas a la API.
- etcd : almacenamiento de datos, persistente, consistente y distribuido. Es la base de datos de Kubernetes y el almacenamiento de valores clave donde mantiene el estado completo de los clústeres (cada cambio se registra aquí). Componentes como el Programador o el Administrador del controlador dependen de esta fecha para saber qué cambios se han producido (recursos disponibles de los nodos, número de pods en ejecución …)
- Administrador de controladores en la nube : Es el controlador específico para controles de flujo y aplicaciones, es decir, si tiene clústeres en AWS u OpenStack.
Tenga en cuenta que, dado que puede haber varios nodos (que ejecutan varios pods), también puede haber varios procesos maestros cuyo acceso al servidor Api equilibre la carga y su etcd esté sincronizado.
Volúmenes:
Cuando un pod crea datos que no deberían perderse cuando el pod desaparece, debe almacenarse en un volumen físico. Kubernetes permite adjuntar un volumen a un pod para conservar los datos . El volumen puede estar en la máquina local o en un almacenamiento remoto . Si está ejecutando pods en diferentes nodos físicos, debe usar un almacenamiento remoto para que todos los pods puedan acceder a él.
Otras configuraciones:
- ConfigMap : puede configurar URL para acceder a los servicios. El pod obtendrá datos de aquí para saber cómo comunicarse con el resto de servicios (pods). Tenga en cuenta que este no es el lugar recomendado para guardar las credenciales.
- Secreto : este es el lugar para almacenar datos secretos como contraseñas, claves API … codificados en B64. El pod podrá acceder a estos datos para usar las credenciales requeridas.
- Implementaciones : aquí es donde se indican los componentes que ejecutará kubernetes. Por lo general, un usuario no trabajará directamente con los pods, los pods se abstraen en ReplicaSets (número de los mismos pods replicados), que se ejecutan a través de implementaciones. Tenga en cuenta que las implementaciones son para aplicaciones sin estado . La configuración mínima para una implementación es el nombre y la imagen que se ejecutará.
- StatefulSet : este componente está diseñado específicamente para aplicaciones como bases de datos que necesitan acceder al mismo almacenamiento .
- Ingress : esta es la configuración que se utiliza para exponer la aplicación públicamente con una URL . Tenga en cuenta que esto también se puede hacer utilizando servicios externos, pero esta es la forma correcta de exponer la aplicación.
- Si implementa un Ingress, deberá crear controladores de Ingress . El controlador de ingreso es un pod que será el punto final que recibirá las solicitudes, las verificará y las equilibrará con los servicios. el controlador de ingreso enviará la solicitud según las reglas de ingreso configuradas . Tenga en cuenta que las reglas de ingreso pueden apuntar a diferentes rutas o incluso subdominios a diferentes servicios internos de Kubernetes.
- Una mejor práctica de seguridad sería utilizar un equilibrador de carga en la nube o un servidor proxy como punto de entrada para no tener expuesta ninguna parte del clúster de Kubernetes.
- Cuando se recibe una solicitud que no coincide con ninguna regla de entrada, el controlador de entrada la dirigirá al » backend predeterminado «. Puede
describeel controlador de entrada para obtener la dirección de este parámetro. minikube addons enable ingress
- Si implementa un Ingress, deberá crear controladores de Ingress . El controlador de ingreso es un pod que será el punto final que recibirá las solicitudes, las verificará y las equilibrará con los servicios. el controlador de ingreso enviará la solicitud según las reglas de ingreso configuradas . Tenga en cuenta que las reglas de ingreso pueden apuntar a diferentes rutas o incluso subdominios a diferentes servicios internos de Kubernetes.
Infraestructura PKI – Autoridad certificadora CA:
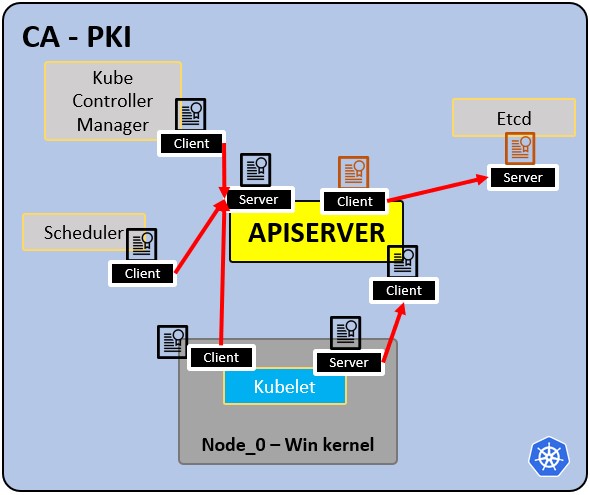
- CA es la raíz de confianza para todos los certificados dentro del clúster.
- Permite que los componentes se validen entre sí.
- Todos los certificados de clúster están firmados por la CA.
- ETCd tiene su propio certificado.
- tipos:
- apiserver cert.
- kubelet cert.
- programador cert.
Minikube
Minikube se puede utilizar para realizar algunas pruebas rápidas en kubernetes sin necesidad de implementar un entorno completo de kubernetes. Ejecutará los procesos maestro y de nodo en una sola máquina . Minikube usará virtualbox para ejecutar el nodo. Vea aquí cómo instalarlo .
$ minikube start
😄 minikube v1.19.0 on Ubuntu 20.04
✨ Automatically selected the virtualbox driver. Other choices: none, ssh
💿 Downloading VM boot image ...
> minikube-v1.19.0.iso.sha256: 65 B / 65 B [-------------] 100.00% ? p/s 0s
> minikube-v1.19.0.iso: 244.49 MiB / 244.49 MiB 100.00% 1.78 MiB p/s 2m17.
👍 Starting control plane node minikube in cluster minikube
💾 Downloading Kubernetes v1.20.2 preload ...
> preloaded-images-k8s-v10-v1...: 491.71 MiB / 491.71 MiB 100.00% 2.59 MiB
🔥 Creating virtualbox VM (CPUs=2, Memory=3900MB, Disk=20000MB) ...
🐳 Preparing Kubernetes v1.20.2 on Docker 20.10.4 ...
▪ Generating certificates and keys ...
▪ Booting up control plane ...
▪ Configuring RBAC rules ...
🔎 Verifying Kubernetes components...
▪ Using image gcr.io/k8s-minikube/storage-provisioner:v5
🌟 Enabled addons: storage-provisioner, default-storageclass
🏄 Done! kubectl is now configured to use "minikube" cluster and "default" namespace by defaul
$ minikube status
host: Running
kubelet: Running
apiserver: Running
kubeconfig: Configured
---- ONCE YOU HAVE A K8 SERVICE RUNNING WITH AN EXTERNAL SERVICE -----
$ minikube service mongo-express-service
(This will open your browser to access the service exposed port)
$ minikube delete
🔥 Deleting "minikube" in virtualbox ...
💀 Removed all traces of the "minikube" clusterConceptos básicos de Kubectl
Kubectles la herramienta de línea de comandos para los clústeres de Kubernetes. Se comunica con el servidor Api del proceso maestro para realizar acciones en kubernetes o para solicitar datos.
kubectl version #Get client and server version
kubectl get pod
kubectl get services
kubectl get deployment
kubectl get replicaset
kubectl get secret
kubectl get all
kubectl get ingress
kubectl get endpoints
#kubectl create deployment <deployment-name> --image=<docker image>
kubectl create deployment nginx-deployment --image=nginx
#Access the configuration of the deployment and modify it
#kubectl edit deployment <deployment-name>
kubectl edit deployment nginx-deployment
#Get the logs of the pod for debbugging (the output of the docker container running)
#kubectl logs <replicaset-id/pod-id>
kubectl logs nginx-deployment-84cd76b964
#kubectl describe pod <pod-id>
kubectl describe pod mongo-depl-5fd6b7d4b4-kkt9q
#kubectl exec -it <pod-id> -- bash
kubectl exec -it mongo-depl-5fd6b7d4b4-kkt9q -- bash
#kubectl describe service <service-name>
kubectl describe service mongodb-service
#kubectl delete deployment <deployment-name>
kubectl delete deployment mongo-depl
#Deploy from config file
kubectl apply -f deployment.ymlEjemplos de archivos de configuración YAML
Cada archivo de configuración tiene 3 partes: metadatos , especificación (lo que debe iniciarse), estado (estado deseado). Dentro de la especificación del archivo de configuración de implementación, puede encontrar la plantilla definida con una nueva estructura de configuración que define la imagen a ejecutar:

Ejemplo de Despliegue + Servicio declarado en el mismo archivo de configuración (desde aquí )
Como un servicio generalmente está relacionado con una implementación, es posible declarar ambos en el mismo archivo de configuración (el servicio declarado en esta configuración solo es accesible internamente):
apiVersion: apps/v1
kind: Deployment
metadata:
name: mongodb-deployment
labels:
app: mongodb
spec:
replicas: 1
selector:
matchLabels:
app: mongodb
template:
metadata:
labels:
app: mongodb
spec:
containers:
- name: mongodb
image: mongo
ports:
- containerPort: 27017
env:
- name: MONGO_INITDB_ROOT_USERNAME
valueFrom:
secretKeyRef:
name: mongodb-secret
key: mongo-root-username
- name: MONGO_INITDB_ROOT_PASSWORD
valueFrom:
secretKeyRef:
name: mongodb-secret
key: mongo-root-password
---
apiVersion: v1
kind: Service
metadata:
name: mongodb-service
spec:
selector:
app: mongodb
ports:
- protocol: TCP
port: 27017
targetPort: 27017Ejemplo de configuración de servicio externo
Este servicio será accesible externamente (verifique los atributos nodePorty type: LoadBlancer):
---
apiVersion: v1
kind: Service
metadata:
name: mongo-express-service
spec:
selector:
app: mongo-express
type: LoadBalancer
ports:
- protocol: TCP
port: 8081
targetPort: 8081
nodePort: 30000INFO:
Esto es útil para las pruebas, pero para la producción solo debe tener servicios internos y un Ingress para exponer la aplicación.
Ejemplo de archivo de configuración de Ingress
Esto expondrá la aplicación en formato http://dashboard.com.
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: dashboard-ingress
namespace: kubernetes-dashboard
spec:
rules:
- host: dashboard.com
http:
paths:
- backend:
serviceName: kubernetes-dashboard
servicePort: 80Ejemplo de archivo de configuración de secretos
Tenga en cuenta cómo las contraseñas están codificadas en B64 (¡que no es seguro!)
apiVersion: v1
kind: Secret
metadata:
name: mongodb-secret
type: Opaque
data:
mongo-root-username: dXNlcm5hbWU=
mongo-root-password: cGFzc3dvcmQ=Ejemplo de ConfigMap
Un ConfigMap es la configuración que se le da a los pods para que sepan cómo ubicar y acceder a otros servicios. En este caso, cada pod sabrá que el nombre mongodb-servicees la dirección de un pod con el que pueden comunicarse (este pod ejecutará un mongodb):
apiVersion: v1
kind: ConfigMap
metadata:
name: mongodb-configmap
data:
database_url: mongodb-serviceLuego, dentro de una configuración de implementación, esta dirección se puede especificar de la siguiente manera para que se cargue dentro del env del pod:
[...]
spec:
[...]
template:
[...]
spec:
containers:
- name: mongo-express
image: mongo-express
ports:
- containerPort: 8081
env:
- name: ME_CONFIG_MONGODB_SERVER
valueFrom:
configMapKeyRef:
name: mongodb-configmap
key: database_url
[...]Ejemplo de configuración de volumen
Puede encontrar diferentes ejemplos de archivos yaml de configuración de almacenamiento en https://gitlab.com/nanuchi/youtube-tutorial-series/-/tree/master/kubernetes-volumes . Tenga en cuenta que los volúmenes no están dentro de los espacios de nombres.
Espacios de nombres
Kubernetes admite varios clústeres virtuales respaldados por el mismo clúster físico. Estos clústeres virtuales se denominan espacios de nombres . Están pensados para su uso en entornos con muchos usuarios repartidos en varios equipos o proyectos. Para los clústeres con unos pocos o decenas de usuarios, no debería necesitar crear ni pensar en espacios de nombres en absoluto. Solo debes comenzar a usar espacios de nombres para tener un mejor control y organización de cada parte de la aplicación implementada en kubernetes.Los espacios de nombres proporcionan un ámbito para los nombres. Los nombres de los recursos deben ser únicos dentro de un espacio de nombres, pero no entre espacios de nombres. Los espacios de nombres no se pueden anidar unos dentro de otros y cada recurso de Kubernetes solo puede estar en un espacio de nombres .Hay 4 espacios de nombres de forma predeterminada si está utilizando minikube:
kubectl get namespace
NAME STATUS AGE
default Active 1d
kube-node-lease Active 1d
kube-public Active 1d
kube-system Active 1dkube-system : no está destinado a ser utilizado por los usuarios y no debes tocarlo. Es para procesos master y kubectl.
kube-public : fecha de acceso público. Contiene un mapa de configuración que contiene información del clúster
kube-node-lease : determina la disponibilidad de un nodo
predeterminado : el espacio de nombres que el usuario utilizará para crear recursos
#Create namespace
kubectl create namespace my-namespaceINFO:
Tenga en cuenta que la mayoría de los recursos de Kubernetes (por ejemplo, pods, servicios, controladores de replicación y otros) se encuentran en algunos espacios de nombres. Sin embargo, otros recursos como los recursos de espacio de nombres y los recursos de bajo nivel, como nodos y persistenVolumes, no están en un espacio de nombres. Para ver qué recursos de Kubernetes están y qué no están en un espacio de nombres:
kubectl api-resources --namespaced=true #In a namespace
kubectl api-resources --namespaced=false #Not in a namespacePuede guardar el espacio de nombres para todos los comandos kubectl posteriores en ese contexto.1
kubectl config set-context --current --namespace=<insert-namespace-name-here>Helm
Helm es el administrador de paquetes de Kubernetes. Permite empaquetar archivos YAML y distribuirlos en repositorios públicos y privados. Estos paquetes se denominan Helm Charts .
helm search <keyword>Helm también es un motor de plantillas que permite generar archivos de configuración con variables:

Pentesting Kubernetes desde fuera
Pentesting Kubernetes desde fuera
Vulnerabilidades y configuraciones incorrectas
Enumeración dentro de un Pod
Si logra comprometer un Pod, lea la siguiente página para aprender cómo enumerar e intentar escalar privilegios / escapar :Enumeración de un pod
Secretos de Kubernetes
Un secreto es un objeto que contiene datos sensibles como una contraseña, un token o una clave. De lo contrario, dicha información podría incluirse en una especificación de Pod o en una imagen. Los usuarios pueden crear secretos y el sistema también crea secretos. El nombre de un objeto secreto debe ser un nombre de subdominio DNS válido . Lea aquí la documentación oficial .Los secretos pueden ser cosas como:
- API, claves SSH.
- Tokens de OAuth.
- Credenciales, contraseñas (texto sin formato o encriptación b64 +).
- Información o comentarios.
- Código de conexión a la base de datos, cadenas….
Hay diferentes tipos de secretos en KubernetesTipo incorporadoUsoOpacodatos arbitrarios definidos por el usuario (predeterminado)kubernetes.io/service-account-tokentoken de cuenta de serviciokubernetes.io/dockercfgarchivo ~ / .dockercfg serializadokubernetes.io/dockerconfigjsonarchivo serializado ~ / .docker / config.jsonkubernetes.io/basic-authcredenciales para autenticación básicakubernetes.io/ssh-authcredenciales para la autenticación SSHkubernetes.io/tlsdatos para un cliente o servidor TLSbootstrap.kubernetes.io/tokendatos del token de arranqueEl tipo opaco es el predeterminado, el par clave-valor típico definido por los usuarios.Cómo funcionan los secretos:
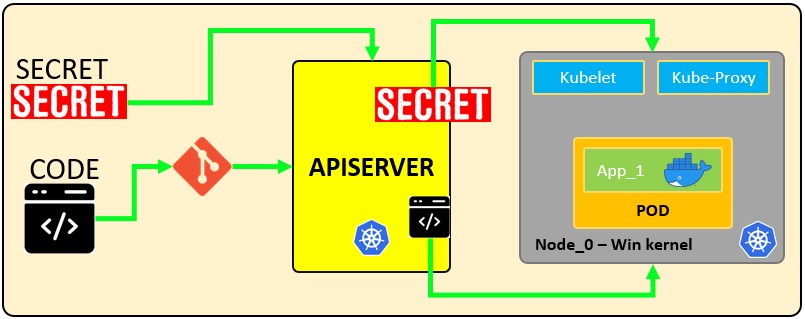
El siguiente archivo de configuración define un secreto llamado mysecretcon 2 pares clave-valor username: YWRtaW4=y password: MWYyZDFlMmU2N2Rm. También define una vaina llamada secretpodque tendrá el usernamey passwordse define en la mysecretexpuesta en las variables de entorno y . También montará el secreto dentro de la ruta con permisos. SECRET_USERNAMESECRET_PASSWORusernamemysecret/etc/foo/my-group/my-username0640
secretpod.yaml
apiVersion: v1
kind: Secret
metadata:
name: mysecret
type: Opaque
data:
username: YWRtaW4=
password: MWYyZDFlMmU2N2Rm
---
apiVersion: v1
kind: Pod
metadata:
name: secretpod
spec:
containers:
- name: secretpod
image: nginx
env:
- name: SECRET_USERNAME
valueFrom:
secretKeyRef:
name: mysecret
key: username
- name: SECRET_PASSWORD
valueFrom:
secretKeyRef:
name: mysecret
key: password
volumeMounts:
- name: foo
mountPath: "/etc/foo"
restartPolicy: Never
volumes:
- name: foo
secret:
secretName: mysecret
items:
- key: username
path: my-group/my-username
mode: 0640kubectl apply -f <secretpod.yaml>
kubectl get pods #Wait until the pod secretpod is running
kubectl exec -it secretpod -- bash
env | grep SECRET && cat /etc/foo/my-group/my-username && echoSecretos en etcd
etcd es un almacén de valores clave coherente y de alta disponibilidad que se utiliza como almacén de respaldo de Kubernetes para todos los datos del clúster. Accedemos a los secretos almacenados en etcd:
cat /etc/kubernetes/manifests/kube-apiserver.yaml | grep etcdVerá que los certificados, claves y URL se encuentran en el FS. Una vez que lo obtenga, podrá conectarse a etcd.1
#ETCDCTL_API=3 etcdctl --cert <path to client.crt> --key <path to client.ket> --cacert <path to CA.cert> endpoint=[<ip:port>] health
ETCDCTL_API=3 etcdctl --cert /etc/kubernetes/pki/apiserver-etcd-client.crt --key /etc/kubernetes/pki/apiserver-etcd-client.key --cacert /etc/kubernetes/pki/etcd/etcd/ca.cert endpoint=[127.0.0.1:1234] healthUna vez que logre establecer comunicación, podrá obtener los secretos:1
#ETCDCTL_API=3 etcdctl --cert <path to client.crt> --key <path to client.ket> --cacert <path to CA.cert> endpoint=[<ip:port>] get <path/to/secret>
ETCDCTL_API=3 etcdctl --cert /etc/kubernetes/pki/apiserver-etcd-client.crt --key /etc/kubernetes/pki/apiserver-etcd-client.key --cacert /etc/kubernetes/pki/etcd/etcd/ca.cert endpoint=[127.0.0.1:1234] get /registry/secrets/default/secret_02Agregar cifrado al ETCD
De forma predeterminada, todos los secretos se almacenan en texto sin formato dentro de etcd, a menos que aplique una capa de cifrado. El siguiente ejemplo se basa en
cifrado.yaml
apiVersion: apiserver.config.k8s.io/v1
kind: EncryptionConfiguration
resources:
- resources:
- secrets
providers:
- aescbc:
keys:
- name: key1
secret: cjjPMcWpTPKhAdieVtd+KhG4NN+N6e3NmBPMXJvbfrY= #Any random key
- identity: {}Después de eso, debe configurar el --encryption-provider-configindicador en el kube-apiserverpara que apunte a la ubicación del archivo de configuración creado. Puede modificar /etc/kubernetes/manifest/kube-apiserver.yamly agregar las siguientes líneas:
containers:
- command:
- kube-apiserver
- --encriyption-provider-config=/etc/kubernetes/etcd/<configFile.yaml>Desplácese hacia abajo en el volumen
- mountPath: /etc/kubernetes/etcd
name: etcd
readOnly: trueDesplácese hacia abajo en el volumen Se monta a hostPath:
- hostPath:
path: /etc/kubernetes/etcd
type: DirectoryOrCreate
name: etcdVerificando que los datos estén encriptados
Los datos se cifran cuando se escriben en etcd. Después de reiniciar su kube-apiserver, cualquier secreto recién creado o actualizado debe encriptarse cuando se almacene. Para comprobarlo, puede utilizar el etcdctlprograma de línea de comandos para recuperar el contenido de su secreto.
- 1 .Cree un nuevo secreto llamado
secret1en eldefaultespacio de nombres:
kubectl create secret generic secret1 -n default --from-literal=mykey=mydata2 – Usando la línea de comando etcdctl, lea ese secreto de etcd:ETCDCTL_API=3 etcdctl get /registry/secrets/default/secret1 [...] | hexdump -Cdonde [...]deben estar los argumentos adicionales para conectarse al servidor etcd.
3 .Verifique que el secreto almacenado tenga el prefijo, lo k8s:enc:aescbc:v1:que indica que el aescbcproveedor ha cifrado los datos resultantes.
4 .Verifique que el secreto esté correctamente descifrado cuando se recupere a través de la API:
kubectl describe secret secret1 -n default- debe coincidir
mykey: bXlkYXRh, mydata está codificado, verifique la decodificación de un secreto para decodificar completamente el secreto.
Dado que los secretos se cifran al escribir, realizar una actualización de un secreto cifrará ese contenido:
kubectl get secrets --all-namespaces -o json | kubectl replace -f -Consejos finales:
- Trate de no guardar secretos en el FS, consígalos en otros lugares.
- Consulte https://www.vaultproject.io/ para agregar más protección a sus secretos.
- https://kubernetes.io/docs/concepts/configuration/secret/#risks
- https://docs.cyberark.com/Product-Doc/OnlineHelp/AAM-DAP/11.2/en/Content/Integrations/Kubernetes_deployApplicationsConjur-k8s-Secrets.htm
Endurecimiento RBAC
Kubernetes tiene un módulo de autorización llamado Control de acceso basado en roles ( RBAC ) que ayuda a establecer permisos de uso para el servidor API. La tabla RBAC se construye a partir de » Roles » y » ClusterRoles «. La diferencia entre ellos es solo dónde se aplicará el rol: un » Rol » otorgará acceso a un solo espacio de nombres específico , mientras que un » ClusterRole » se puede usar en todos los espacios de nombres en el clúster. Además, ClusterRoles también puede otorgar acceso a:
- recursos de ámbito de clúster (como nodos).
- puntos finales sin recursos (como / healthz).
- recursos con espacios de nombres (como Pods), en todos los espacios de nombres.
Ejemplo de configuración de roles :
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: defaultGreen
name: pod-and-pod-logs-reader
rules:
- apiGroups: [""]
resources: ["pods", "pods/log"]
verbs: ["get", "list", "watch"]Ejemplo de configuración de ClusterRole :Por ejemplo, puede usar ClusterRole para permitir que un usuario en particular ejecute:
kubectl get pods --all-namespacesapiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
# "namespace" omitted since ClusterRoles are not namespaced
name: secret-reader
rules:
- apiGroups: [""]
resources: ["secrets"]
verbs: ["get", "watch", "list"]Concepto de vinculación de roles y roles de clústerUn enlace de rol otorga los permisos definidos en un rol a un usuario o conjunto de usuarios . Contiene una lista de sujetos (usuarios, grupos o cuentas de servicio) y una referencia al rol que se otorga. Un RoleBinding otorga permisos dentro de un espacio de nombres específico, mientras que un ClusterRoleBinding otorga ese acceso a todo el clúster . Ejemplo de RoleBinding :
apiVersion: rbac.authorization.k8s.io/v1
# This role binding allows "jane" to read pods in the "default" namespace.
# You need to already have a Role named "pod-reader" in that namespace.
kind: RoleBinding
metadata:
name: read-pods
namespace: default
subjects:
# You can specify more than one "subject"
- kind: User
name: jane # "name" is case sensitive
apiGroup: rbac.authorization.k8s.io
roleRef:
# "roleRef" specifies the binding to a Role / ClusterRole
kind: Role #this must be Role or ClusterRole
name: pod-reader # this must match the name of the Role or ClusterRole you wish to bind to
apiGroup: rbac.authorization.k8s.ioEjemplo de ClusterRoleBinding :1
apiVersion: rbac.authorization.k8s.io/v1
# This cluster role binding allows anyone in the "manager" group to read secrets in any namespace.
kind: ClusterRoleBinding
metadata:
name: read-secrets-global
subjects:
- kind: Group
name: manager # Name is case sensitive
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: ClusterRole
name: secret-reader
apiGroup: rbac.authorization.k8s.ioLos permisos son aditivos, por lo que si tiene un clusterRole con «listar» y «eliminar» secretos, puede agregarlo con un rol con «get». Así que tenga en cuenta y pruebe siempre sus roles y permisos y especifique lo que está PERMITIDO, porque todo está DENEGADO por defecto.
Estructura RBAC
El permiso de RBAC se basa en tres partes individuales:
- 1 .Role \ ClusterRole: el permiso real. Contiene reglas que representan un conjunto de permisos. Cada regla contiene recursos y verbos . El verbo es la acción que se aplicará al recurso.
- 2 .Asunto (usuario, grupo o cuenta de servicio): el objeto que recibirá los permisos.
- 3 .RoleBinding \ ClusterRoleBinding: la conexión entre Role \ ClusterRole y el sujeto.
Así es como se verá en un clúster real:
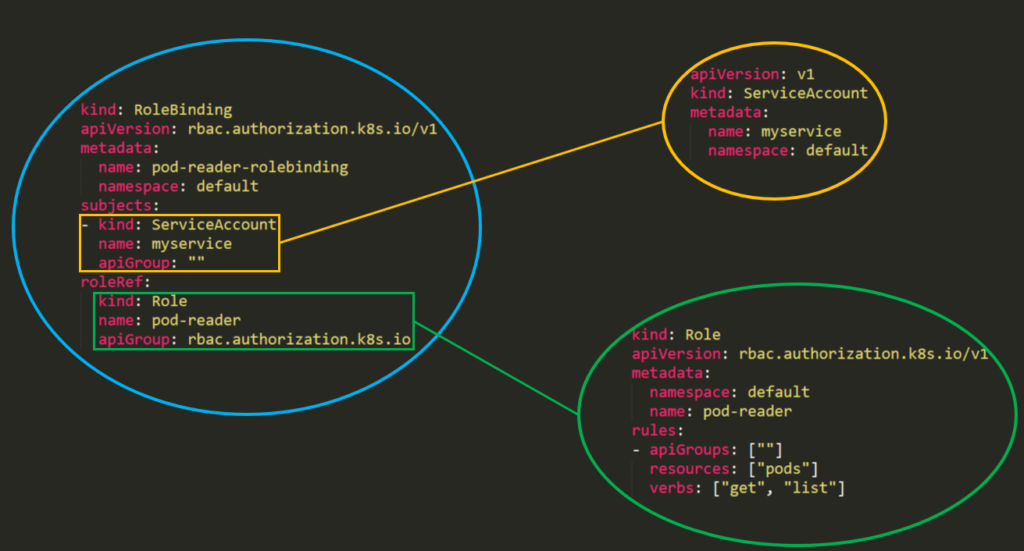
«Los enlaces de roles detallados brindan mayor seguridad , pero requieren más esfuerzo para administrar «.Desde Kubernetes 1.6 en adelante, las políticas RBAC están habilitadas de forma predeterminada . Pero para habilitar RBAC puede usar algo como:
kube-apiserver --authorization-mode=Example,RBAC --other-options --more-optionsEsto está habilitado por defecto. Funciones RBAC:
- Restrinja el acceso a los recursos a los usuarios o ServiceAccounts.
- Un rol de RBAC o ClusterRole contiene reglas que representan un conjunto de permisos.
- Los permisos son puramente aditivos (no hay reglas de «denegación»).
- RBAC funciona con roles y enlaces
Al configurar roles y permisos, es muy importante seguir siempre el principio de privilegios mínimos.
Fortalecimiento de las cuentas de servicio
Para obtener más información sobre el refuerzo de cuentas de servicio, lea la página:
Fortalecimiento de API de Kubernetes
Es muy importante proteger el acceso al servidor Kubernetes Api, ya que un actor malintencionado con suficientes privilegios podría abusar de él y dañar de muchas formas el medio ambiente. Es importante asegurar tanto el acceso ( orígenes de la lista blanca para acceder al servidor API y denegar cualquier otra conexión) como la autenticación (siguiendo el principio de privilegio mínimo ). Y definitivamente nunca permita solicitudes anónimas . Proceso de solicitud común: Usuario o Cuenta de servicio de K8s -> Autenticación -> Autorización -> Control de admisión.Consejos :
- Cerrar puertos.
- Evite el acceso anónimo.
- NodeRestriction; Sin acceso desde nodos específicos a la API.
- https://kubernetes.io/docs/reference/access-authn-authz/admission-controllers/#noderestriction
- Básicamente evita que los kubelets agreguen / eliminen / actualicen etiquetas con un prefijo node-restriction.kubernetes.io/. Este prefijo de etiqueta está reservado para que los administradores etiqueten sus objetos de nodo con fines de aislamiento de carga de trabajo, y los kubelets no podrán modificar etiquetas con ese prefijo.
- Y también, permite a los kubelets agregar / eliminar / actualizar estas etiquetas y prefijos de etiquetas.
- Garantice con etiquetas el aislamiento seguro de la carga de trabajo.
- Evite pods específicos del acceso a la API.
- Evite la exposición de ApiServer a Internet.
- Evite el acceso no autorizado RBAC.
- Puerto ApiServer con firewall y listas blancas de IP.
Endurecimiento del contexto de seguridad
De forma predeterminada, se utilizará el usuario root cuando se inicie un Pod si no se especifica ningún otro usuario. Puede ejecutar su aplicación dentro de un contexto más seguro usando una plantilla similar a la siguiente:
apiVersion: v1
kind: Pod
metadata:
name: security-context-demo
spec:
securityContext:
runAsUser: 1000
runAsGroup: 3000
fsGroup: 2000
volumes:
- name: sec-ctx-vol
emptyDir: {}
containers:
- name: sec-ctx-demo
image: busybox
command: [ "sh", "-c", "sleep 1h" ]
securityContext:
runAsNonRoot: true
volumeMounts:
- name: sec-ctx-vol
mountPath: /data/demo
securityContext:
allowPrivilegeEscalation: true- https://kubernetes.io/docs/tasks/configure-pod-container/security-context/
- https://kubernetes.io/docs/concepts/policy/pod-security-policy/
Endurecimiento general
Debe actualizar su entorno de Kubernetes con la frecuencia necesaria para tener:
- Dependencias actualizadas.
- Parches de seguridad y errores.
Ciclos de lanzamiento : Cada 3 meses hay una nueva versión menor – 1.20.3 = 1 (Major) 0,20 (menor) 0,3 (parche)La mejor forma de actualizar un clúster de Kubernetes es (desde aquí ):
- Actualice los componentes del nodo maestro siguiendo esta secuencia:
- etcd (todas las instancias).
- kube-apiserver (todos los hosts del plano de control).
- kube-controller-manager.
- kube-planificador.
- administrador del controlador en la nube, si usa uno.
- Actualice los componentes del Worker Node, como kube-proxy, kubelet.
Referencias
https://book.hacktricks.xyz/pentesting/pentesting-kubernetes